Issue 2551114
Created on 2021-03-03 11:12 by schlatterbeck, last changed 2021-03-12 11:24 by schlatterbeck.
| Files | ||||
|---|---|---|---|---|
| File name | Uploaded | Description | Edit | Remove |
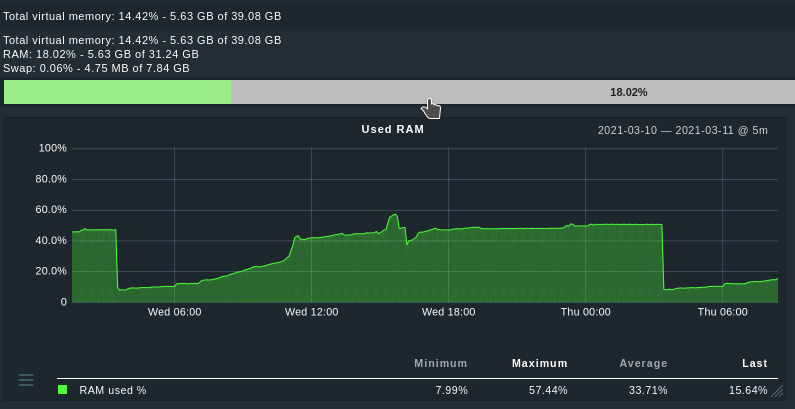
| Time_Tracker_RAM_Tagesverlauf.png | schlatterbeck, 2021-03-12 11:24 | RAM usage during the day | ||
{kind=link}
| Messages | |||
|---|---|---|---|
| msg7084 | Author: [hidden] (schlatterbeck) | Date: 2021-03-03 11:12 | |
I'm experiencing memory problems with a PostgreSQL backend, especially when using filter_iter instead of filter. This is now traced to psycopg by default using client-side cursors: https://www.psycopg.org/docs/usage.html#server-side-cursors These consume the whole query-result at the client resulting in huge roundup client processes (in our case WSGI but this can be reproduced with the built-in standalone roundup server). We typically get a memory consumption of several GB with only 15 WSGI processes. In single cases with filter_iter (where a *large* result-set was obtained) we got a single WSGI process of several GB or even an out-of-memory condition. The roundup server in that case already has 32GB of memory. For some time we have turned off that WSGI processes are restarted every 30 requests. Since that change our WSGI processes have grown *a lot*. This is because these do not return memory once consumed to the operating system. So once a single large query is executed the WSGI process stays big. The fix would be simple: psycopg implements server-side cursors as named cursors, so every call to connection.cursor() would need a name argument. Since filter calls are not executed in parallel (even a threading implementation in a web-server which is not recommended for python anyway uses separate connections for different threads) this change can be implemented with a fixed name per filter or filter_iter call. What do you think: Since this only affects postgres (mysql seems to have non-buffered cursors by default where the result is never fully materialized at the client) this should be straightforward to implement. Should we make this configurable (for postgres backend only)? If yes, should the server-side cursor be the default? My opinion is that it should be configurable and that the server-side (new implementation) should be the default. |
|||
| msg7085 | Author: [hidden] (schlatterbeck) | Date: 2021-03-04 11:57 | |
I've now implemented in changeset 6a6b4651be1f. Changed tests test equivalence of results with both, client-side and server-side cursor in postgres. |
|||
| msg7086 | Author: [hidden] (rouilj) | Date: 2021-03-04 20:46 | |
Hi Ralf: Ralf Schlatterbeck added the comment: >I've now implemented in changeset 6a6b4651be1f. >Changed tests test equivalence of results with both, client-side >and server-side cursor in postgres. In the initial post, you make a case for the connection name as a static value. Does that info have to be included as a comment in the code somewhere so others won't be confused by a static name? In back_postgresql.py the sql_new_cursor method has an argument name='default'. But there is no code to make sure that it was called with a real cursor name. Should there be a check and exception thrown if name == 'default'? Do we need code in configuration.py that enforces serverside_cursor = no if you are not using postgres and if so, is 'yes' the right default? I think the call to self.db.sql_new_cursor(name='filter') in rdbms_common.py is called for all backends: sqlite mysql and postgres right? Why is there no need for: sql_new_cursor(self, name, conn, *args, *(kw)) for other rdbms backends besides postgres? I see you are testing and comparing both server side and client side cursors. Is it possible we could get different answers based on the amount of data returned? That is the server says "hey I only have 4 rows returned, I'll push the 4 rows and kill the serve side cursor?". So that server side cursor on a small data set is the same as client side cursor? I am pushing to CI now. Pleakse keep an eye on https://travis-ci.org/github/roundup-tracker/roundup in case there are issues. Thanks for identify fixing this. Sadly bpo could probably use this but since they are moving away from roundup ... |
|||
| msg7087 | Author: [hidden] (schlatterbeck) | Date: 2021-03-05 10:06 | |
On Thu, Mar 04, 2021 at 08:46:44PM +0000, John Rouillard wrote: > > In the initial post, you make a case for the connection name as a > static value. Does that info have to be included as a comment in the > code somewhere so others won't be confused by a static name? No the static value is hard coded (for filter, filter_iter and _materialize_multilink I'm using different hard-coded values) > In back_postgresql.py the sql_new_cursor method has an argument > name='default'. But there is no code to make sure that it was called > with a real cursor name. Should there be a check and exception thrown > if name == 'default'? The cursor is dynamically created by sql_new_cursor. So 'default' would be a valid name. > Do we need code in configuration.py that enforces serverside_cursor = > no if you are not using postgres and if so, is 'yes' the right > default? The code is written in a way that doesn't use that config variable for other sql backends, see the implementation of sql_new_cursor in backends/rdbms_common.py vs. backends/back_postgresql.py, the latter ignores the cursor name in the default implementation. > I think the call to self.db.sql_new_cursor(name='filter') in > rdbms_common.py is called for all backends: sqlite mysql and postgres > right? Why is there no need for: > > sql_new_cursor(self, name, conn, *args, *(kw)) > > for other rdbms backends besides postgres? It is called with the name for all backends but the default implementation ignores the parameter in the sql_new_cursor method in backends/rdbms_common.py. I've looked into mysql, there server-side cursors without "buffering" seem to be the default. There are named cursors in mysql but they do not seem to be related with client-side vs. server-side cursors as in psycopg. Note that I think making client-side cursors the default in psycopg is a bad design decision. It certainly surprised me that the roundup-server process grew by 1GB just after issuing the SQL statement :-) I haven't looked into what sqlite does in this regard. Since sqlite cannot do parallel queries (!) I would think that the first performance optimization would be to replace sqlite with another backend anyway. > I see you are testing and comparing both server side and client side > cursors. Is it possible we could get different answers based on the > amount of data returned? That is the server says "hey I only have 4 > rows returned, I'll push the 4 rows and kill the serve side > cursor?". So that server side cursor on a small data set is the same > as client side cursor? The results should never be different. By default a server-side cursor in Postgres fetches 2000 results in one go, the parameter of the cursor is called "itersize" and is configurable. So for small query results server-side vs. client-side cursors are identical in behaviour. Only if the result-set is larger than the itersize will the client repeatedly fetch from the server-side cursor. > I am pushing to CI now. Pleakse keep an eye on > https://travis-ci.org/github/roundup-tracker/roundup in case there are > issues. Thanks! Looks like everything passes. (I *did* run the tests on python2.7 and 3.7 before pushing). > Thanks for identify fixing this. Sadly bpo could probably use this but > since they are moving away from roundup ... Yes, I still think it's an error to move to a commercially hosted tracker where it is questionable if it won't become a vendor lockin data silo when the company behind it changes policies. Ralf -- Dr. Ralf Schlatterbeck Tel: +43/2243/26465-16 Open Source Consulting www: www.runtux.com Reichergasse 131, A-3411 Weidling email: office@runtux.com |
|||
| msg7095 | Author: [hidden] (rouilj) | Date: 2021-03-10 15:38 | |
Hi Ralf: If you are satisfied that this is fixed, can you close it out please. Thanks. -- rouilj |
|||
| msg7098 | Author: [hidden] (schlatterbeck) | Date: 2021-03-12 11:24 | |
The attached picture shows the memory consumption during a day after the fix. Before the fix this would max out at 32GB from time to time. Individual WSGI processes still use 700MB but do not grow beyond that. I haven't yet investigated this still quite large value but at least the do not grow to several GB (per process!) now. |
|||
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2021-03-12 11:24:05 | schlatterbeck | set | status: new -> closed resolution: fixed messages: + msg7098 files: + Time_Tracker_RAM_Tagesverlauf.png |
| 2021-03-10 15:38:55 | rouilj | set | messages: + msg7095 |
| 2021-03-05 10:06:46 | schlatterbeck | set | messages: + msg7087 |
| 2021-03-04 20:46:44 | rouilj | set | messages: + msg7086 |
| 2021-03-04 11:57:21 | schlatterbeck | set | assignee: schlatterbeck messages: + msg7085 |
| 2021-03-03 11:12:26 | schlatterbeck | create | |