Issue 2550811
Created on 2013-05-11 17:39 by shammash, last changed 2019-06-16 01:22 by rouilj.
| Files | ||||
|---|---|---|---|---|
| File name | Uploaded | Description | Edit | Remove |
| roundup-r4962-issue811-ber1.patch | ber, 2015-01-20 22:13 | |||
| roundup_-_jinja2.png | techtonik, 2015-01-28 11:55 | |||
| roundup_-_jinja2.svg | techtonik, 2015-01-28 11:55 | |||
| unnamed | techtonik, 2015-04-13 14:20 | |||
{kind=link}
{kind=link}
| Messages | |||
|---|---|---|---|
| msg4889 | Author: [hidden] (shammash) | Date: 2013-05-11 17:39 | |
I am trying the latest roundup from bitbucket mercurial and I've noticed some problems with unicode. Here's how to reproduce: - start a demo instance: python demo.py -t jinja2 nuke - login and create a new issue - in the "change note" add some unicode characters, like "à" - click to submit - stacktrace appears |
|||
| msg4890 | Author: [hidden] (shammash) | Date: 2013-05-11 17:42 | |
And this is the exception:
Templating Error
<type 'exceptions.UnicodeDecodeError'>: 'ascii' codec can't decode byte 0xc3 in position 0: ordinal not in range(128)
Debugging information follows
Full traceback:
Traceback (most recent call last):
File "/Users/shammash/src/ai/bugs/roundup/cgi/client.py", line 1125, in renderContext
result = pt.render(self, None, None, **args)
File "/Users/shammash/src/ai/bugs/roundup/cgi/engine_jinja2.py", line 78, in render
return self._tpl.render(c).encode(client.charset, )
File "/usr/local/lib/python2.7/site-packages/jinja2/environment.py", line 894, in render
return self.environment.handle_exception(exc_info, True)
File "/Users/shammash/src/ai/bugs/demo/html/issue.item.html", line 1, in top-level template code
{% extends 'layout/page.html' %}
File "/Users/shammash/src/ai/bugs/demo/html/layout/page.html", line 19, in top-level template code
{% block page_content %}
File "/Users/shammash/src/ai/bugs/demo/html/layout/page.html", line 44, in block "page_content"
{% block content %}
File "/Users/shammash/src/ai/bugs/demo/html/issue.item.html", line 67, in block "content"
<pre>{{ msg.content.hyperlinked() }}</pre>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 0: ordinal not in range(128)
|
|||
| msg4892 | Author: [hidden] (pcaulagi) | Date: 2013-05-13 06:22 | |
The following change will solve the problem for Jinja2 -
➜ roundup hg diff
diff -r 8aa3175fb6ae roundup/cgi/templating.py
--- a/roundup/cgi/templating.py Sat May 11 21:22:39 2013 +0530
+++ b/roundup/cgi/templating.py Sat May 11 21:31:51 2013 +0530
@@ -1398,7 +1398,7 @@
if not escape:
s = cgi.escape(s)
s = self.hyper_re.sub(self._hyper_repl, s)
- return s
+ return unicode(s, 'utf-8')
def wrapped(self, escape=1, hyperlink=1):
"""Render a "wrapped" representation of the property.
➜ roundup
However, this doesn't work with the other engines.
In other words, I don't know if we are specifying an encoding explicitly
but are just using str() in cgi/templating.py (def plain). I am going
to look around some more to see how to fix the problem.
|
|||
| msg4895 | Author: [hidden] (shammash) | Date: 2013-05-19 11:17 | |
Another unicode issue, slightly different: - start a demo instance: python demo.py -t jinja2 nuke - login and create a new issue - this time in in the "title" add some unicode characters, like "à" - click to submit - stacktrace appears |
|||
| msg4896 | Author: [hidden] (shammash) | Date: 2013-05-19 11:23 | |
Rendering of the form values in the request also has problems. I've modified the jinja2 template to pre-fill the change note using from values like this:
- <textarea name="@note" rows="5" class='input-xxlarge' id='change_note'></textarea>
+ <textarea name="@note" rows="5" class='input-xxlarge' id='change_note'>{% if request.form.note %}{{ request.form.note.value }}{% endif %}</textarea>
And when I pass a note containing unicode characters I get the usual UnicodeDecodeError .
|
|||
| msg4897 | Author: [hidden] (ber) | Date: 2013-05-19 17:54 | |
Hi Shammash, thanks for testing. Can you give the stacktrace? |
|||
| msg4898 | Author: [hidden] (shammash) | Date: 2013-05-19 19:13 | |
Stacktrace for the title issue:
Traceback (most recent call last):
File "/Users/shammash/src/ai/bugs/roundup/cgi/client.py", line 1125, in renderContext
result = pt.render(self, None, None, **args)
File "/Users/shammash/src/ai/bugs/roundup/cgi/engine_jinja2.py", line 78, in render
return self._tpl.render(c).encode(client.charset, )
File "/usr/local/lib/python2.7/site-packages/jinja2/environment.py", line 894, in render
return self.environment.handle_exception(exc_info, True)
File "/Users/shammash/src/ai/bugs/demo/html/issue.item.html", line 1, in top-level template code
{% extends 'layout/page.html' %}
File "/Users/shammash/src/ai/bugs/demo/html/layout/page.html", line 19, in top-level template code
{% block page_content %}
File "/Users/shammash/src/ai/bugs/demo/html/layout/page.html", line 44, in block "page_content"
{% block content %}
File "/Users/shammash/src/ai/bugs/demo/html/issue.item.html", line 27, in block "content"
{% include 'issue.item.edit.html' %}
File "/Users/shammash/src/ai/bugs/demo/html/issue.item.edit.html", line 92, in top-level template code
<a href='{{ context.copy_url() }}'>{{ i18n.gettext('Make a copy') }}</a>
File "/Users/shammash/src/ai/bugs/roundup/cgi/templating.py", line 1164, in copy_url
for key, value in query.items()])
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/urllib.py", line 1250, in quote
return ''.join(map(quoter, s))
KeyError: u'\xe0'
|
|||
| msg4899 | Author: [hidden] (shammash) | Date: 2013-05-19 19:18 | |
Stacktrace when using "http://localhost:8917/demo/issue?@template=item¬e=à" after changing the template as described. Traceback (most recent call last): File "/Users/shammash/src/ai/bugs/roundup/cgi/client.py", line 1125, in renderContext result = pt.render(self, None, None, **args) File "/Users/shammash/src/ai/bugs/roundup/cgi/engine_jinja2.py", line 78, in render return self._tpl.render(c).encode(client.charset, ) File "/usr/local/lib/python2.7/site-packages/jinja2/environment.py", line 894, in render return self.environment.handle_exception(exc_info, True) File "/Users/shammash/src/ai/bugs/demo/html/issue.item.html", line 1, in top-level template code {% extends 'layout/page.html' %} File "/Users/shammash/src/ai/bugs/demo/html/layout/page.html", line 19, in top-level template code {% block page_content %} File "/Users/shammash/src/ai/bugs/demo/html/layout/page.html", line 44, in block "page_content" {% block content %} File "/Users/shammash/src/ai/bugs/demo/html/issue.item.html", line 27, in block "content" {% include 'issue.item.edit.html' %} File "/Users/shammash/src/ai/bugs/demo/html/issue.item.edit.html", line 74, in top-level template code <textarea name="@note" rows="5" class='input-xxlarge' id='change_note'>{% if request.form.note %}{{ request.form.note.value }}{% endif %}</textarea> UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 0: ordinal not in range(128) |
|||
| msg4924 | Author: [hidden] (antmail) | Date: 2013-09-16 14:34 | |
I've also got unicode codec error.
When i'm trying to create issue with title with non-ascii characters
i've got:
Traceback (most recent call last):
File "/usr/local/lib/python2.7/site-packages/roundup/cgi/client.py",
line 1122, in renderContext
result = pt.render(self, None, None, **args)
File "/usr/local/lib/python2.7/site-packages/roundup/cgi/
engine_jinja2.py", line 78, in render
return self._tpl.render(c).encode('utf-8', )
File "/usr/local/lib/python2.7/site-packages/jinja2/environment.py",
line 969, in render
exc_info = sys.exc_info()
File "/usr/local/lib/python2.7/site-packages/jinja2/environment.py",
line 742, in handle_exception
exc_type, exc_value, tb = traceback.standard_exc_info
File "/usr/local/www/r2/html/issue.item.html", line 1, in top-level
template code
{% extends 'layout/page.html' %}
File "/usr/local/www/r2/html/layout/page.html", line 17, in top-level
template code
{% block page_content %}
File "/usr/local/www/r2/html/layout/page.html", line 42, in block
"page_content"
{% block content %}
File "/usr/local/www/r2/html/issue.item.html", line 67, in block
"content"
<pre>{{ msg.content.hyperlinked() }}</pre>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xd0 in position 0:
ordinal not in range(128)
I'm ensure that all form-data are utf-8 encoded. Also i applied patch
from msg4892. But no luck.
I don't fully understand where and why 'ascii' codec is used.
|
|||
| msg4925 | Author: [hidden] (antmail) | Date: 2013-09-18 15:38 | |
I've solved problem using site-wide configuration:
echo "import sys; sys.setdefaultencoding('utf-8')" > /usr/local/lib/
python2.7/site-packages/sitecustomize.py
|
|||
| msg4926 | Author: [hidden] (pcaulagi) | Date: 2013-09-21 08:55 | |
For some reason, the mails were in my spam folder. I will take a look. Anthony, from what I remember, the encoding is already set to 'utf-8'. I am not sure we need to change something outside roundup. |
|||
| msg4927 | Author: [hidden] (antmail) | Date: 2013-09-23 10:36 | |
Default Python charset is 'utf-8' only for version 3 as i found in many documents. I was trying to investigate roundup code and remove various decode and str(). But then error appears in different place and when it was on _socket_op(self.request.wfile.write, str(content)) in client.py i gave up. I don't fully understand a conception of charset handling in roundup. Things, like - client.py (write_html) if self.charset != self.STORAGE_CHARSET: content = content.decode(self.STORAGE_CHARSET, 'replace') content = content.encode(self.charset, 'xmlcharrefreplace') - engine_jinja2.py (render) return self._tpl.render(c).encode(client.charset, ) are implying that all output will follow a client preferred charset. But roundup templates prepared by a roundup administrator usually contain predefined ' <meta http-equiv="Content-Type" content="text/html; charset=X">' in they content, as seemed to me. |
|||
| msg5190 | Author: [hidden] (ber) | Date: 2015-01-17 23:02 | |
I believe the main problem stems from that roundup saves utf-8 encoded strings to its database and jinja2 uses unicode strings internally. When a value from the database is called from the jinja2 engine while processing a template, it gets utf-8 and treats it as str. References: http://www.roundup-tracker.org/docs/upgrading.html#migrating-from-0-6-to-0-7 "Added internationalization support. This is done via encoding all data stored in roundup database to utf- 8 (unicode encoding)." http://jinja.pocoo.org/docs/dev/api/#unicode "Jinja2 is using Unicode internally which means that you have to pass Unicode objects to the render function or bytestrings that only consist of ASCII characters. " "For Jinja2 the default encoding of templates is assumed to be utf-8." Charset for the client: At a later stage it seems that a way was added to encode the result of roundup to the charset that the client requested. But this seems to be handled inconsistently in some templates. It probably should be solved consistently. So I suggest to come up with a test case where the current thing fails and create an extra issue for it. Potential solution to the unicode errors: We could make sure that all variables from roundup are unicode objects when called from the jinja2 engine. Either at the roundup end or transform it at the jinja2 end. We could add a custom jinja2 filter that does the utf-8 to unicode conversion and then add it to each call to tje jinja template where a string is to be returned. If we call the custom filter 'u' it would look like "{{ msg.content.hyperlinked()|u }} jjinja2 itself cannot know if the function will return a str or something different. |
|||
| msg5191 | Author: [hidden] (ber) | Date: 2015-01-20 22:13 | |
roundup-r4962-issue811-ber1.patch shows how to create a translation function that depends on the loaded template engine. I'm using it in one place, but a) there are other places b) and this breaks other functions where still utf-8 is required. Basically this patch is a concept, it may show that using the jinja2 filter approach may be more feasable if there is too much breakage this way. |
|||
| msg5192 | Author: [hidden] (ber) | Date: 2015-01-21 07:35 | |
The solution sketched in my roundup-r4962-issue811-ber1.patch
will not be good enough. The problem is: functions like .plain()
will be called from within templating.py as well, so we get a mixture
of str and unicode objects and some functions do not like unicode
objects.
For example urllib.quote will not like them and barf.
I've also tested solutions using functions like .plainu(), but this will get too
ugly. So I believe the solution should be to use a custom jinja2 filter to do
unicode conversion on each variable call.
Note that some objects will just be called from jinja2 and then use str() to
get its string value. Example {{context.title}}
|
|||
| msg5194 | Author: [hidden] (antmail) | Date: 2015-01-21 11:16 | |
Sorry, msg5193 to be deleted. |
|||
| msg5195 | Author: [hidden] (techtonik) | Date: 2015-01-28 11:55 | |
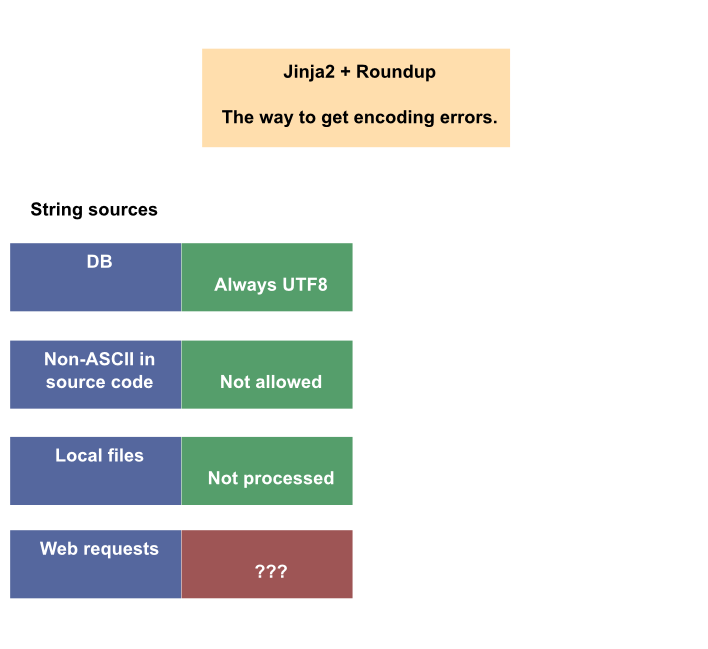
The root of the problem as it seems to me is that Roundup doesn't process user input as UTF-8 internally. It stores strings in DB as UTF8, but doesn't do this for user input. So, my best guess us that text user input should be converted to unicode as soon as it is submitted, and before being output for validation. Where is the code that converts output to UTF8 for database? When does it happen? Attached is a picture of where the error may come from, drawn in Inkscape of you want to fix it. |
|||
| msg5196 | Author: [hidden] (ber) | Date: 2015-01-28 21:34 | |
Am Mittwoch, 28. Januar 2015, 11:55:01 schrieben Sie: > It stores strings in DB as > UTF8, but doesn't do this for user input. Hmmm.. I've checked the db file contents and it was in utf8. Actually the str objects are in utf-8, that is why the encoding() function needs to know that it is a str with utf-8 encoding. I think an okay solution would be to a) write a test case that fills in strings with utf-8 and tries to render all templates from "jinja2" template to check for errors. b) use an custom filter "u()" and add it to almost all template calls where the result is needed as text. Problem: Some calls with end up with str objects, other with roundup objects where jinja2 seems to call str() on them. So my testing u() function needs to accomodate for this. |
|||
| msg5197 | Author: [hidden] (techtonik) | Date: 2015-01-29 19:16 | |
On Thu, Jan 29, 2015 at 12:34 AM, Bernhard Reiter <issues@roundup-tracker.org> wrote: > > Hmmm.. I've checked the db file contents and it was in utf8. > Actually the str objects are in utf-8, that is why the encoding() function > needs to know that it is a str with utf-8 encoding. Do you mean that msg.content.hyperlinked() here is UTF8? <pre>{{ msg.content.hyperlinked() }}</pre> And that Jinja2 fails, because it expects unicode() object, and not binary string that is UTF8? > I think an okay solution would be to > a) write a test case that fills in strings with utf-8 and tries to render > all templates from "jinja2" template to check for errors. > b) use an custom filter "u()" and add it to almost all template calls > where the result is needed as text. Problem: Some calls with end up with > str objects, other with roundup objects where jinja2 seems to call str() > on them. So my testing u() function needs to accomodate for this. What if we make Roundup use unicode objects internally instead of binary str with UTF-8? It will solve the problem and make it forward compatible with Python 3. For now the solution may be to patch Jinja2 to assume that all raw strings are in UTF8 and not ASCII (which I think is only logical). |
|||
| msg5198 | Author: [hidden] (techtonik) | Date: 2015-01-29 19:21 | |
This seems to be a place for patching: https://github.com/mitsuhiko/jinja2/commit/06badebe3b0985c9fe3365ab446f690d1af3a512#diff-65d3fed441e0bee9895176265b373c3bR577 It won't break ASCII parsing, but will enable UTF8. Am I right? |
|||
| msg5199 | Author: [hidden] (ber) | Date: 2015-01-30 08:14 | |
> Do you mean that msg.content.hyperlinked() here is UTF8?
> <pre>{{ msg.content.hyperlinked() }}</pre>
> And that Jinja2 fails, because it expects unicode() object, and
> not binary string that is UTF8?
Yes, this is my current understanding, which my testing supported.
(I've written a patch that does encode(x,"utf-8") in some places
and it worked (up to a point) but supported by hypothesis.)
> What if we make Roundup use unicode objects internally instead of
> binary str with UTF-8? It will solve the problem and make it forward
> compatible with Python 3.
This would be a major undertaking which puts all other places
of roundup in danger of failing. Within templating roundup calls
its own functions and it assumes utf-8 everywhere, so just changing a few
points does not to it (tried it with a patch).
It is an option at some time in the future of course. :)
> For now the solution may be to patch Jinja2
> to assume that all raw strings are in UTF8 and not ASCII (which I
> think is only logical).
I thought about this, too. The drawback is that we have to bring
our own version of jinja2. In my installation jinja2 comes from the
distribution. The other solution with the customer filter functions
works okay, and the extra |u at places is bearable and can be easily replaced
with a dummy function or removed in the future.
|
|||
| msg5213 | Author: [hidden] (ber) | Date: 2015-02-16 16:09 | |
My plan is to first write a new test in a new test file that tries to render all template files of the jinja2 subdirectory once. Then I am adding a custom filter called "u" that will either render a python string object from utf-8 into unicode object or call str() on other python objects before encoding. Then adding all "|u" custom filters to the jinja2 template, satisfying the test. I've started coding the test using a full setup from db_test_base which many tests do, but only with one databasebackend. |
|||
| msg5214 | Author: [hidden] (ber) | Date: 2015-02-16 16:46 | |
I have to learn more about how to write roundup tests, in order to be visible I've made remarks to test/README.txt and added a test_jinja2.py stub and pushed both to hg:4964:2c3cc4ccd024 |
|||
| msg5215 | Author: [hidden] (ber) | Date: 2015-02-16 16:47 | |
Sorry for the nose, hg:4964 should work or hg:2c3cc4ccd024 |
|||
| msg5288 | Author: [hidden] (techtonik) | Date: 2015-03-17 21:49 | |
I think that maybe doing sys.defaultencoding('utf-8') and checking for
it when using Jinja2 templates is the best solution.. In the end, Roundup
is an application and it is not itself imported.
|
|||
| msg5289 | Author: [hidden] (ber) | Date: 2015-03-18 08:17 | |
On Monday 23 February 2015 at 18:48:47, anatoly techtonik wrote: > >> For a unicode issue, we should try to set sys.defaultencoding to utf-8 > >> http://stackoverflow.com/questions/28642781/hack-jinja2-to-encode-from- utf- 8-instead-of-ascii I that fails (I expect Zope templates being a > >> pain), then we can try to limit the change only to new templates. Or > >> gradually move to use > >> unicode objects internally. > > > > Thanks for the hint, I have to visit this one. > > See also > https://stackoverflow.com/questions/28657010/dangers-of-sys- setdefaultencodingutf-8 I have not looked at what it does so far, I was busy fixing the email comparison tests that were broken (see issue2550869 and issue2550877). :) But I am done with that. It maybe a good solution or not, I don't have an opinion on it yet. Anyway I first like to have a test written that tries to render each template onces with some values, this way we can avoid obvious problems and see if it actually works. My testing has convinced me that manual testing it quite a lot of work does not give you much assurance in this case. |
|||
| msg5290 | Author: [hidden] (techtonik) | Date: 2015-03-18 09:08 | |
On Wed, Mar 18, 2015 at 11:18 AM, Bernhard Reiter <issues@roundup-tracker.org> wrote: > > Anyway I first like to have a test written that tries to render each template > onces with some values, this way we can avoid obvious problems and see if it > actually works. My testing has convinced me that manual testing it quite a lot of > work does not give you much assurance in this case. Putting tests first is a good solution. We already have a manual test in bug report, the question now is how to insert that into the test system. A possible solution for testing the web frontend is to use https://github.com/kevin1024/vcrpy The main problem is encoding of strings that are passed to Jinja2 indirectly, such as object properties, including external objects, such as request variables. |
|||
| msg5292 | Author: [hidden] (ber) | Date: 2015-03-19 08:30 | |
On Wednesday 18 March 2015 at 10:08:58, anatoly techtonik wrote: > the question now is how to insert that into the test > system. My idea is to create demo data that contains unicode/utf-8 characters for all fields and then to render each template file and look for Exceptions. I've done a number of manual tests, they are easy to do, but hard to get complete, because each field could possibly accessed with a number of ways. Help is appreciated, next steps: a) create entries in the demo database, for this extend TestCase.setup() in test_jinja2 and just add the data. b) find out where the standard template is placed and accessed from test_jinja2. c) add a first test that only renders index.html or so. d) add tests that render more template files. |
|||
| msg5304 | Author: [hidden] (techtonik) | Date: 2015-04-13 14:20 | |
I've got some more proposals on StackOverflow: 1. Decode into Unicode at ORM (HyperDB) level 2. Use https://pypi.python.org/pypi/unicode-nazi As for demo data, I think it is possible to ask bugs.python.org guys for a copy of database for testing. |
|||
| msg5305 | Author: [hidden] (ber) | Date: 2015-04-14 06:41 | |
Hi Anatoly, thanks for keeping pushing the issue and giving new suggestions! :) On Monday 13 April 2015 at 16:20:24, anatoly techtonik wrote: > 1. Decode into Unicode at ORM (HyperDB) level If we found the right place, this is something we can try. So far I've found the option less appealing from my (very limited) code staring and poking, it just feels to me like this is the wrong place adding a special path there. My plan of doing a) a demo set with unicode chars in each field b) then using a translation function seems cleaner to me with a little less risk. Just has to be done. > 2. Use https://pypi.python.org/pypi/unicode-nazi Looks like a module that can be helpful to unicode problems, especially if we would want to migrate roundup to complete unicode which would be a major refactoring. > As for demo data, I think it is possible to ask bugs.python.org > guys for a copy of database for testing. We do have our database as well. Both databases are probably good to test some more entries. My idea for a) is that I fill out each field of the "classic" (or jinja2) template at least once with some unicode chars, this makes it a small fixture to base other automated tests on. Probably easy to do, just needs to be done. Best, Bernhard |
|||
| msg5349 | Author: [hidden] (jerrykan) | Date: 2015-08-10 12:18 | |
In the announcement notes Jinja2 is listed as experimental in v1.5, which I take to mean that it isn't fully supported. Given that v1.5 was released over 2 years ago, at this point I believe it is probably more important to cut a new release (v1.5.1) than to try and fix this bug in a part of the code that isn't meant for production use yet. |
|||
| msg5352 | Author: [hidden] (ber) | Date: 2015-08-10 13:38 | |
On Monday 10 August 2015 at 14:18:37, John Kristensen wrote: > at this point I believe > it is probably more important to cut a new release (v1.5.1) than to try > and fix this bug in a part of the code that isn't meant for production > use yet. I agree, though it would not be that hard to fix I guess. |
|||
| msg5356 | Author: [hidden] (jerrykan) | Date: 2015-08-17 10:15 | |
This is a response to msg5355 in issue2550863 ... On 16/08/15 16:35, anatoly techtonik wrote:> > anatoly techtonik added the comment: > > Thinking about this, I am in favor of recommending UTF-8 mode for Jinja2 > setup. sys.setdefaultencoding('utf-8') sounds like a hack, but I fail to see > where exactly it is harmful. > > http://stackoverflow.com/questions/28657010/dangers-of-sys-setdefaultencodingutf-8 My main concert about implementing this hack is that at best it is just a short-term solution to paper over the real underlying causes (which admittedly I'm not fully across). This has the potential to give people the false impression that the issue is solved and everyone moves on and forgets about it... until some subtle bug comes along that becomes much harder to debug because everyone has forgotten about the hack. At this point we are back at the same point having to fix the underlying issue. If you are suggesting just using the hack for a v1.5.1 release, then I would suggest a better solution might be to document this as a known issue and provide a work-around for those who really want to try out the experimental Jinja2 support. |
|||
| msg5395 | Author: [hidden] (ber) | Date: 2015-12-02 20:12 | |
I still believe my msg5292 to show a feasable and reasonable approach. Just have to be done. So if someone wants to help, get going at the first step. ;) |
|||
| msg5396 | Author: [hidden] (ber) | Date: 2015-12-02 20:14 | |
and then of course we use the filter from msg5190 to fix all occurances. This is future proof, because once we get better unicode handling in a future roundup release, we can use change the filter and all template will still work. It is also a small solution as it just adds "|u" to a number of places in the templates. |
|||
| msg5400 | Author: [hidden] (ber) | Date: 2016-01-05 21:30 | |
Did some reading and cleaned up test_jinja2.py which to be a slightly better stub that does nothing yet. (Learned that the tests are underdocumented, it is a bit unclear which test instructure to use when testing on a certain level from the code comments.) |
|||
| msg5413 | Author: [hidden] (ber) | Date: 2016-01-06 13:31 | |
Within this week I'll submit two things that will make this issue nicely releasable for 1.5.1: a) a jinja2 translation function which can be used to fix the template with some documentation how to do it. b) a hint in the jinja2 template documentation to a wiki page that will have the improvements between the releases. |
|||
| msg5417 | Author: [hidden] (ber) | Date: 2016-01-06 20:32 | |
hg5013:c1443d96ac94 now points to the new wikipage at http://www.roundup-tracker.org/cgi-bin/moin.cgi/Jinja2 |
|||
| msg5418 | Author: [hidden] (ber) | Date: 2016-01-06 21:40 | |
hg5015:85484d35f1a2 now has a custom filter that will either call the method and then convert to unicode or convert to unicode directly. As an example I've added this to the msg contents in issue.item and msg.item. So we are ready to release here because there is a good chance that only updates to the template files itself are necessary now. Like adding "|u" to a couple of places. However to do this more systematically we should extend test_jinja2 to render a few non-ascii example date over all templates. |
|||
| msg5419 | Author: [hidden] (ber) | Date: 2016-01-06 21:42 | |
jinja2 may or may not offer a way to add an extension that does this magic at a central place, but just reading the documentation shows that this would involve a much deeper understanding of jinja2. And if it would be that easy, why hasn't nobody added this example somewhere. ;) |
|||
| msg5424 | Author: [hidden] (techtonik) | Date: 2016-01-08 06:10 | |
On Thu, Jan 7, 2016 at 12:40 AM, Bernhard Reiter <issues@roundup-tracker.org> wrote: > Like adding "|u" to a couple of places. I still consider it a hack. I may be miss something again, but I'd like to investigate if it is possible to just override unicode object in Ninja, so that its __add__ and other autoconversion methods used custom encoding explicitly specified for them. Maybe we should use our object wrapper for that. It may also allow to be more flexible with Python 3 unicode/bytes issues. |
|||
| msg5425 | Author: [hidden] (ber) | Date: 2016-01-08 10:16 | |
On Friday 08 January 2016 at 07:10:38, anatoly techtonik wrote: > I still consider it a hack. Yes, I agree it is. Still I consider it a consistent hack that uses an official jinja2 interface and is very likely to not have other side effects. Thus I consider it the best robust, transparent and future proof solution I have come up with (in the time spend on this). > I may be miss something again, but I'd > like to investigate if it is possible to just override unicode object > in Ninja, so that its __add__ and other autoconversion methods > used custom encoding explicitly specified for them. Yes, please investigate. I am hoping that there is a better solution. However as I already commented in msg5419, it may exist but I have not found it easily. |
|||
| msg5426 | Author: [hidden] (techtonik) | Date: 2016-01-08 10:27 | |
I am on it right now. |
|||
| msg6111 | Author: [hidden] (cmeerw) | Date: 2018-07-20 23:53 | |
I have applied |u (and also |e) to the template, see https://bitbucket.org/cmeerw/roundup/branch/jinja2-template |
|||
| msg6149 | Author: [hidden] (cmeerw) | Date: 2018-07-31 21:19 | |
added explicit Unicode encoding to jinja2 template in 56d30f09f205 |
|||
| msg6546 | Author: [hidden] (rouilj) | Date: 2019-06-16 01:22 | |
cmeerw check in |u fixes. |
|||
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2019-06-16 01:22:48 | rouilj | set | status: open -> fixed resolution: fixed messages: + msg6546 nosy: + rouilj versions: + 2.0.0alpha, - devel |
| 2018-07-31 21:19:50 | cmeerw | set | messages: + msg6149 |
| 2018-07-20 23:53:28 | cmeerw | set | nosy:
+ cmeerw messages: + msg6111 |
| 2017-09-27 00:52:14 | rouilj | set | keywords: + patch |
| 2016-01-13 16:23:15 | ber | set | status: new -> open |
| 2016-01-13 16:13:06 | ber | set | keywords: + jinja2, - patch |
| 2016-01-08 10:27:54 | techtonik | set | messages: + msg5426 |
| 2016-01-08 10:16:54 | ber | set | messages: + msg5425 |
| 2016-01-08 06:10:38 | techtonik | set | messages: + msg5424 |
| 2016-01-06 21:42:33 | ber | set | messages: + msg5419 |
| 2016-01-06 21:40:41 | ber | set | messages: + msg5418 |
| 2016-01-06 20:32:55 | ber | set | messages: + msg5417 |
| 2016-01-06 13:31:58 | ber | set | messages: + msg5413 |
| 2016-01-05 21:30:47 | ber | set | messages: + msg5400 |
| 2015-12-02 20:14:10 | ber | set | messages: + msg5396 |
| 2015-12-02 20:12:08 | ber | set | messages: + msg5395 |
| 2015-08-17 10:15:18 | jerrykan | set | messages: + msg5356 |
| 2015-08-10 13:38:47 | ber | set | messages: + msg5352 |
| 2015-08-10 12:18:37 | jerrykan | set | nosy:
+ jerrykan messages: + msg5349 |
| 2015-04-14 06:41:24 | ber | set | messages: + msg5305 |
| 2015-04-13 14:20:24 | techtonik | set | files:
+ unnamed messages: + msg5304 |
| 2015-03-19 08:30:23 | ber | set | messages: + msg5292 |
| 2015-03-18 09:08:58 | techtonik | set | messages: + msg5290 |
| 2015-03-18 08:17:59 | ber | set | messages: + msg5289 |
| 2015-03-17 21:49:40 | techtonik | set | messages: + msg5288 |
| 2015-02-16 16:47:30 | ber | set | messages: + msg5215 |
| 2015-02-16 16:46:25 | ber | set | messages: + msg5214 |
| 2015-02-16 16:09:39 | ber | set | messages: + msg5213 |
| 2015-01-30 08:14:38 | ber | set | messages: + msg5199 |
| 2015-01-29 19:21:54 | techtonik | set | messages: + msg5198 |
| 2015-01-29 19:16:58 | techtonik | set | messages: + msg5197 |
| 2015-01-28 21:34:17 | ber | set | messages: + msg5196 |
| 2015-01-28 11:55:28 | techtonik | set | files: + roundup_-_jinja2.svg |
| 2015-01-28 11:55:01 | techtonik | set | files:
+ roundup_-_jinja2.png nosy: + techtonik messages: + msg5195 |
| 2015-01-28 10:09:06 | techtonik | set | messages: - msg5193 |
| 2015-01-21 11:16:44 | antmail | set | messages: + msg5194 |
| 2015-01-21 11:13:36 | antmail | set | messages: + msg5193 |
| 2015-01-21 07:35:07 | ber | set | assignee: pcaulagi -> ber |
| 2015-01-21 07:35:01 | ber | set | messages: + msg5192 |
| 2015-01-20 22:13:33 | ber | set | files:
+ roundup-r4962-issue811-ber1.patch keywords: + patch |
| 2015-01-20 22:13:14 | ber | set | messages: + msg5191 |
| 2015-01-17 23:02:06 | ber | set | messages: + msg5190 |
| 2015-01-17 20:40:08 | ber | link | issue2550863 dependencies |
| 2015-01-17 20:37:58 | ber | set | priority: high |
| 2013-09-23 10:36:17 | antmail | set | messages: + msg4927 |
| 2013-09-21 08:55:21 | pcaulagi | set | messages: + msg4926 |
| 2013-09-18 15:38:52 | antmail | set | messages: + msg4925 |
| 2013-09-16 14:34:47 | antmail | set | nosy:
+ antmail messages: + msg4924 |
| 2013-05-19 19:18:08 | shammash | set | messages: + msg4899 |
| 2013-05-19 19:13:55 | shammash | set | messages: + msg4898 |
| 2013-05-19 17:54:12 | ber | set | messages: + msg4897 |
| 2013-05-19 11:23:37 | shammash | set | messages: + msg4896 |
| 2013-05-19 11:17:55 | shammash | set | messages: + msg4895 |
| 2013-05-13 09:07:28 | ber | set | nosy: + ber |
| 2013-05-13 06:22:04 | pcaulagi | set | messages: + msg4892 |
| 2013-05-12 08:15:12 | pcaulagi | set | assignee: pcaulagi nosy: + pcaulagi |
| 2013-05-11 17:42:30 | shammash | set | messages: + msg4890 |
| 2013-05-11 17:39:37 | shammash | create | |